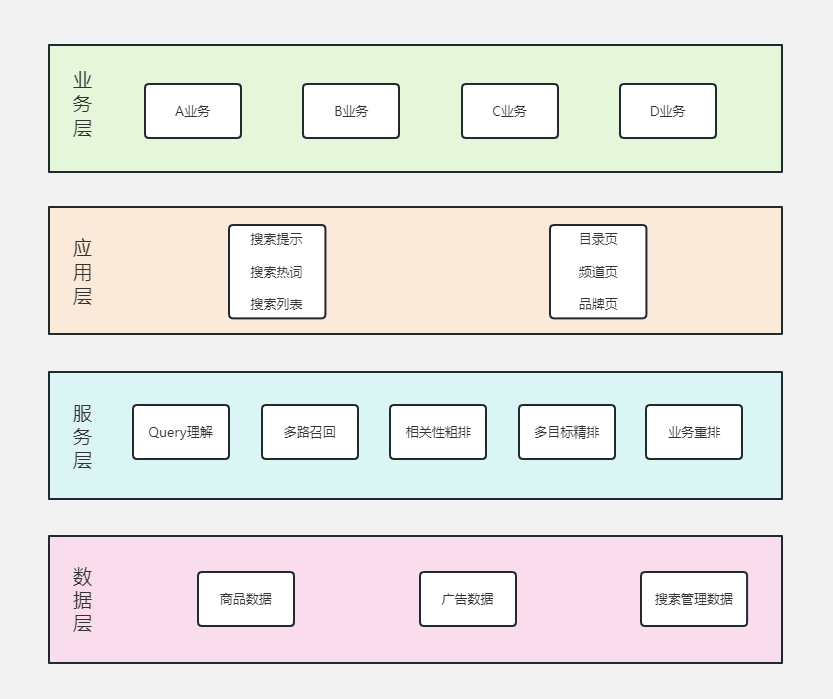
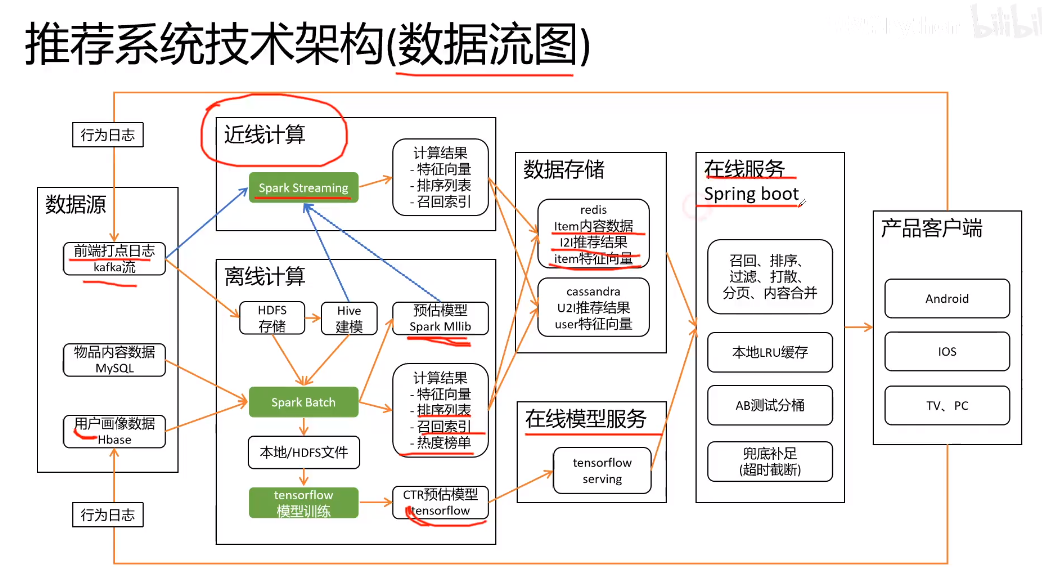
架构设计
Netflix 架构设计
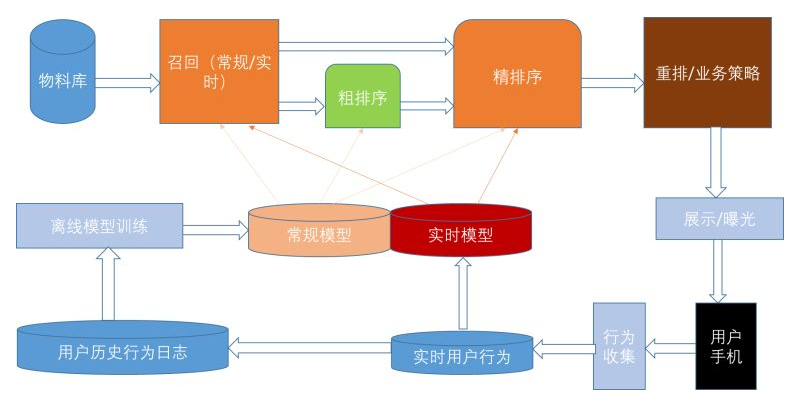
首先,我们在下图中展示了推荐系统的总体系统图。该架构的主要组件包含一种或多种机器学习算法。 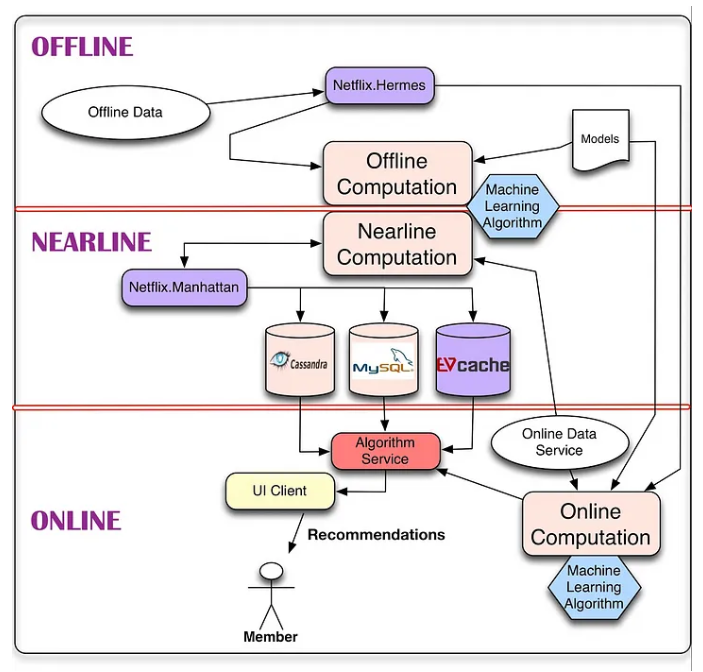
注释版本 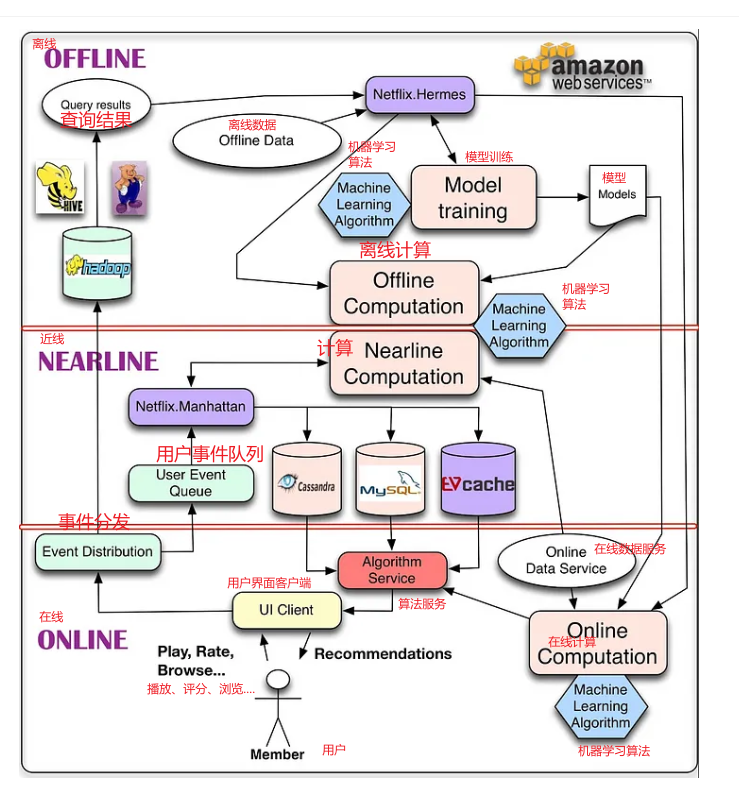
Netflix 把推荐系统拆分成了三部分
它把推荐系统拆成这三部分的本质原因是因为推荐系统本身就是由
数据来决定的.
- 在线部分
- 基于用户属性和场景信息,进行召回打分。并把结果推荐给用户。
- 存储和分发用户和推荐系统的交互信息,用于推荐系统的自我迭代
- 近线部分
- 将算法模型所需要的特征数据存储在 mysql 中,在数据获取上减少延迟推断
- 定时更新,保持特征的实时性。
- 离线部分
- 训练算法模型时, 需要对模型进行大量的数据投喂,才能够获得一定的数据预测能力(向量矩阵打分)
- 我们可以对数据做的最简单的事情就是存储它以供以后离线处理, 大数据相关技术例如 hadoop
- 离线计算对数据量和算法计算复杂度的限制较小,因为它以批处理方式运行,时序要求宽松但是,由于未合并最新数据,因此它很容易在更新之间变得
陈旧。
计算可以离线、近线或在线完成。在线计算可以更好地响应最近的事件和用户交互,但必须实时响应请求。 这会限制所采用算法的计算复杂性以及可以处理的数据量。这也是为什么会存在离线和近线部分的重要原因。
个性化架构中的关键问题之一是如何以无缝方式组合和管理在线和离线计算。
近线计算是这两种模式之间的中间折衷方案,我们可以执行类似在线的计算,但不需要实时提供它们。
模型训练是另一种计算形式,它使用现有数据生成模型,该模型稍后将在实际结果计算过程中使用。
Amazon 架构设计