
以小白的身份了解推荐系统。
推荐系统的实现
推荐系统需要载体, 一般都是以应用的形式出现, 一个完整的推荐系统应该有三部分角色组成。用户、物品提供者、推荐系统网站。
所以一个好的推荐系统应该是三方共赢的系统。不仅仅能够准确的预测出用户的行为,而且能够拓展用户的视野。帮助用户挖掘那些可能感兴趣的物品,
推荐系统在做的事情其实是从主观上的判断感受,转换成客观上的评价指标。
长尾效应: 总的来说就是热门的商品会越来越热门, 新用户往往会购买热门商品, 而老用户则会慢慢转移到冷门商品中
- 用户满意度. 我们可以通过用户的点击率. 停留时长转换率等指标衡量用户的满意度
- 预测准确度. 这是一个度量推荐系统预测用户行为的能力
- 覆盖率。这指的是推荐系统对物品长尾的发掘能力。简单来说就是推荐系统能够推荐出来的物品占总物品集合的比例。
- 多样性 假设我 80% 的时间在看喜剧, 20%的时间在看动漫, 那么推荐系统给我推 10 部影片中, 最好有 8 部喜剧、 2 部动漫
- 新颖性 推荐给用户一些之前没有听说过的物品
- 商业目标 推荐系统更注重网站的商业目标是否达成
推荐系统的一般流程
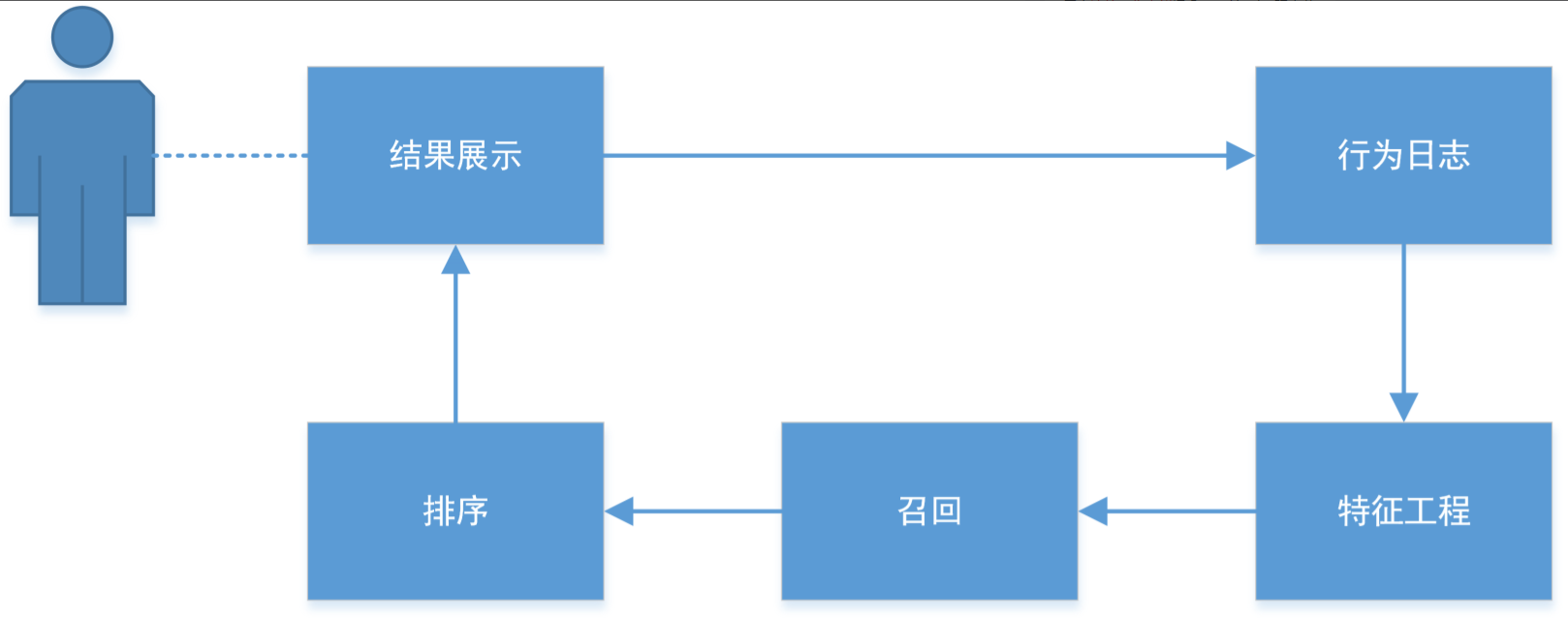
不管是复杂还是简单的推荐系统,基本都包含流程:
- 1)结果展示部分。不管是app还是网页上,会有ui界面用于展示推荐列表。
- 2)行为日志部分。用户的各种行为会被时刻记录并被上传到后台的日志系统,例如点击行为、购买行为、地理位置等等。这些数据后续一般会被进行ETL(extract抽取、transform转换、load加载),供迭代生成新模型进行预测。
- 3)特征工程部分。得到用户的行为数据、物品的特征、场景数据等等,需要人工或自动地去从原始数据中抽取出特征。这些特征作为输入,为后面各类推荐算法提供数据。特征选取很重要,错的特征必定带来错误的结果。
- 4)召回部分。 有了用户的画像,然后利用数据工程和算法的方式,从千万级的产品中锁定特定的候选集合,完成对推荐列表的初步筛选,其在一定程度上决定了排序阶段的效率和推荐结果的优劣。
- 5)排序部分。针对上一步的候选集合,会进行更精细化地打分、排序,同时考虑新颖性、惊喜度、商业利益等的一系列指标,获得一份最终的推荐列表并进行展示。
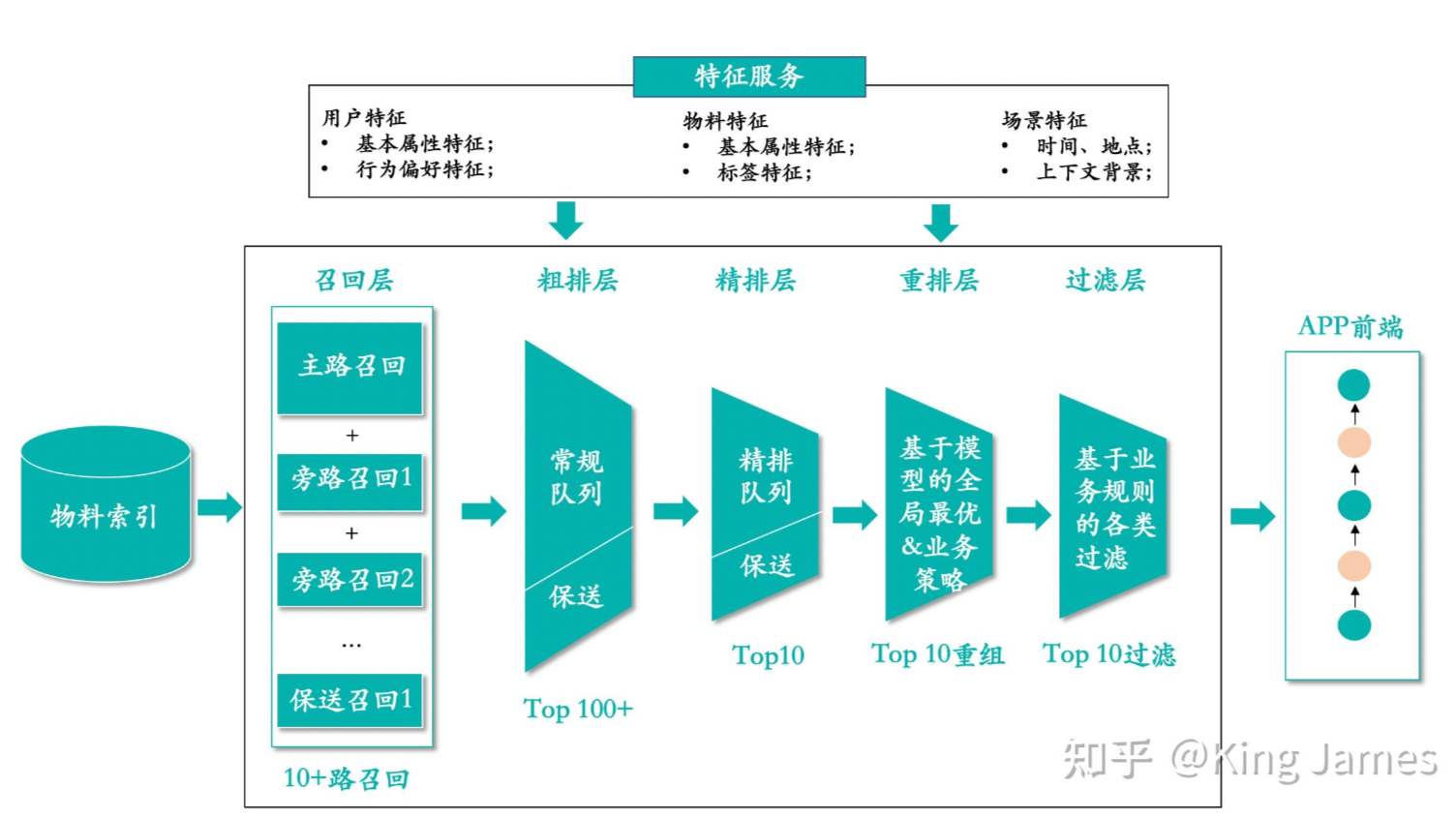
如图可知,推荐系统的核心: 基于 用户特征 、物料特征、场景特征 ,从系统的物品库中,给对应的用户推荐相应的物品,也就是所谓的 千人千面
抽象流程:
- 读取数据
- 读取用户数据、物料数据、场景数据(实时上下文数据)
- 算法打分
- 有算法模型,就意味着存在模型训练。模型训练的数据源从哪里来呢, (离线数据+实时数据)喂给模型
- 业务过滤
- 由业务侧制定的
权重规则
- 由业务侧制定的
- 结果展示
- 按照打分结果展示
将推荐系统架构里面的主要部分拆分出来, 就是以上几个维度。
用户打开 APP 看到为自己推荐的商品,需要经过一系列的流程周转。
物料(独立站侧所有的商品信息)->召回(基于Query找到万/千商品)->粗排序(得到千/百商品)->精排序(精排、计分)->重排序(调整排序,得到百/十商品)->业务策略(业务决策)->过滤(排除)->展示
最终展示在了 APP 前端,为用户做商品推荐的展示。
- 物料: 即所有的商品
- 召回: 在物料中找到符合要求的相关商品 (数量级可能是几万或者几千个商品)
- 粗排: 在召回的基础上大致的过滤
- 精排: 基于向量等操作进行二次过滤
- 重排: 基于精排的结果进行一些调整和打分排序
- 业务策略: 业务人员制定规则, 基于重排的结果进行人工干扰
- 过滤: 某些商品不进行展示
- 展示: 最终返回给前端渲染
名词解释:
召回
名词解释 “召回”(Retrieval)是推荐系统中的第一阶段,指当用户输入查询关键词(Query)后,搜索引擎 首先从海量的商品库中快速找出与该关键词相关的一系列候选商品的过程。推荐召回能够决定推荐系统的上限
这一阶段的目标是尽可能全面且高效地找出所有可能满足用户需求的商品,而不仅仅是精确匹配的结果。
召回机制是推荐系统中常用的算法策略 通过用户的属性和行为来进行数据的筛选和匹配。
它的目标是根据用户的历史浏览记录、购物记录、推测出可能感兴趣的商品从而提供符合用户需求的商品推荐。
与传统的排名方式不同,召回机制更关注匹配度而非明确的排名。
召回机制的目标是提供个性化、精准的商品推荐,让用户能够更轻松的找到自己感兴趣的商品,并提升用户购物体验。(阿里巴巴千人千面)
总而言之, 召回机制是一种基于 用户历史行为 和 兴趣 的算法策略,用于预测和推荐可能感兴趣的商品,并在电商平台等推荐系统中提供个性化精准的商品推荐。
常见的召回策略
- 协同过滤召回
- 内容相似度召回
- 图算法召回
- 热门召回
- 新课召回
排序
使用另一个模型对候选集进行评分和排序。所筛选的子集数据量为万/千。
常见的排序策略
- 机器学习
- 线性回归
- 二分策略
- 逻辑回归
- 梯度提升决策树
- 深度学习网络
重排
考虑最终排名的其他限制
- 删除重复商品
- 删除用户已购买的商品
- 删除已经下线、无库存的商品
- 删除用户明确表示了不感兴趣的商品
- 提高时效内容的得分和权重
- 热门补足:有些新用户,用户行为数据较少,涉及冷启动问题,可以使用一些热门物品进行补足
- 合并内容信息,推荐过程中使用的基本都是物品的 SKU ,此时需要基于 SKU 做数据填充例如相关商品名称、价格、图片等信息
业务决策
业务制定的规则,例如:夏天时针对某些有 tag 标签的商品增加权重
推荐系统怎么知道我喜欢什么?
基于用户行为分析的推荐算法, 那么推荐系统需要基于哪些基础数据来做支撑?
离线行为有日志记录用户点击、页面浏览链路、停留时间、点击、评分、评论。得到这些行为信息进而推测出用户的兴趣
协同过滤算法
- 基于用户的协同过滤算法(User Collaboration Filter,UserCF)。给用户推荐和他兴趣相似的其他用户喜欢的物品。更加社会化
- 基于物品的协同过滤算法(Item Collaboration Filter,ItemCF)。给用户推荐和他之前喜欢的物品相似的物品。更加个性化 (周边、类型类别)
最常用的两种通用召回策略, 基于物品表示向量的相似度召回, 基于 物品 关联规则 (tag) 的召回
- 基于物品表示向量的相似度召回, 物品 Item 的显示画像的表示, 把整个 item 嵌入到向量的表示, 用户-物品的矩阵
- 基于物品关联规则的召回 (常用在电商的购物车页面推荐或者购买页面推荐中), 找出所有用户购买的所有商品数据里频繁出现的 item 排序, 来做频繁集挖掘, 找到满足支持度 (即两个商品被同时购买的概率) 阈值的关联物品. 关联规则中分析的关键概念包括
- 支持度 (Support): 它是两件商品 (A&B) 在总销量 (N) 中出现的概率, 即 A 和 B 同时被购买的概率;
- 置信度 (Confindence): 它是购买 A 后再购买 B 的概率;
- 提升度 (Lift): 它表示先购买 A 对购买 B 的概率的提升作用, 用来判断规则是否有实际价值, 及使用规则后商品在购物车中出现的次数是否高于商品单独出现购物车中的频率
U 2 i 和 i 2 i
- U 2 i : 从用户到 Item
- I 2 i : 从 item 到 item
参考文献
推荐系统系列之推荐系统概览(上) | 亚马逊 AWS 官方博客
【推荐系统系列】Amazon的推荐系统是如何运行的? – Twocups
《推荐系统实战入门》
《个性化推荐系统开发指南》
《从零开始构建企业级推荐系统》