什么是数据结构
- 数据结构就是把数据元素按照一定的关系组织起来的一组集合,用来组织和存储数据。
- 可以理解成 Java 中的 List,Map 等等
- 存储数据的方式(List,Map,数组,链表)
- 任何数据结构都是物理结构上的顺序结构和链式结构
数据结构的分类
逻辑结构
思想上的结构 : 厨房,卧室,卫生间
- 线型结构(链表结构
- 线型结构中的数据元素存在一对一的关系。
- 集合结构(数组结构
- 集合结构中数据元素除了属于同一个集合以外,没有其他的任何关系。
- 树形结构(Tree 结构
- 树形结构中的数据元素存在一对多的层级关系
- 图型结构(多对多结构
- 多对多的数据元素
物理结构
真实的结构: 钢筋混凝土+牛顿力学
- 顺序结构(紧密结构)(数组,特点查询快,增删慢)
- 顺序结构存储的数据单元是连续的
- 顺序存储结构的弊端,就像生活中排队也会有人插队也会有人有特殊情况离开,这时候整个结构都处于变化中,此时就需要链式结构去存储
- 链式结构(跳转结构)(链表,特点增删快,查询慢)
- 把数据元素存放在任意存储单元里,这组存储单元可以是连续的也可以是不连续的。此时数据之间不能反应元素之间的逻辑关系,因此在链表中会在每个元素的前后加上指针,来存放数据元素的地址。
链表结构(树)
AVL
在 AVL 中, 任何节点的两个子树的高度差最大为 1,所以也叫高度平衡树(这个树的层级会很深)
特性
- 对于任何一个子树的 ROOT 节点,左边的数据一定同比右边的数据要小,反而亦之。
- 任何节点的两个子树的高度差最大为 1 数据失衡的处理方式
数据失衡指的是在二叉树中,原本的树结构被打破了。需要重新调整树结构
左旋、右旋。人话版本: (如果根节点被打破了,在老的树形结构中在右边,需要上升到根节点的 Root,这个过程叫右旋)
RBT(红黑树)
和 AVL 很像,数据失衡的处理多了一个变色
B+树
B +树是一种多叉树结构,它的数据结构一般为多个页组成的多层级结构,一般一个页大小为 16 KB, 一个数据页可以放特别多的索引信息,所以扇出很高,每一个索引页都能指向一千多个子页,三层左右就可以存储大概 2 kw 的数据。最多只需要 3 次 IO。
时间复杂度: O (log 2 n)
以主键索引为例,最末级的叶子结点存放行数据。非叶子节点则放的是索引信息(主键 ID 和页号),用于加速查询
以新增数据为例,分为三种情况,
- 新插入的数据不会导致叶子节点和索引节点的变化,这个时候直接进行插入操作
- 新插入的数据会导致叶子节点变化而索引节点吧
调整数据页,叶子节点和非叶子节点都会调整。 叶子和索引节点都没满: 直接加进去 叶子节点满了,索引节点没满: 插入新数据时,调整叶子节点的数据页,往索引节点新增一条数据 叶子节点满了,索引节点满了:插入新数据时,叶子和索引节点的数据都要进行拆分。同时还需要往上层在加入一个新的索引。
B+树的数据页
数据页的结构:
- 页层级信息
- 页的元数据 (页头)
- 前页指针
- 页号
- 后页指针
- 页的行数据
- 行 ID
- 数据值
- 页目录
- 可以通过二分查找的方式,针对当前数据页进行查找。
- 页尾
- 校验码
索引是怎么建立的? 基于上述描述的数据页,每一个数据页里拿一个 ID 最小的数据(只拿 ID),并且记录下这个数据页的页号。组成一个新的数据页。 在这个新的数据页中,加入页层级的信息。这个就是索引
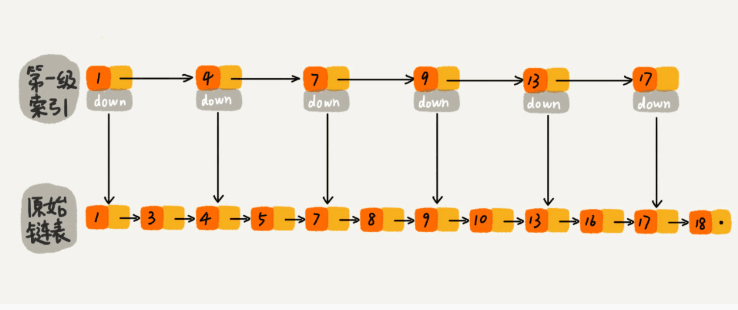
跳表
本质上是一个
链表+多级索引+指针的一个组合,其目的是为了降低链表的循环查找。通过多级索引的方式来间隔出与原始链表的数据差距,通过指针指向原始链表。 通过牺牲空间来获取时间。